
Practically Speaking
If you’ve read this far, you have observed multiple stages of EQ and compression within our hearing system, all leading to an anything but linear frequency response.
The point of all of this is simple: the human ear is specifically and brilliantly designed for the intelligibility of oral communication. If you were to look at the spectral density of the human voice, you’ll notice that the strongest boosts are located around the consonants in human speech (2 kHz to 6 kHz), with little need for anything in the upper and lower ranges – which explains our poor response in those areas.
As audio engineers and technicians, the takeaway for us is pretty clear: in order for us to hear music evenly, some ranges must be compensated for. While it may seem logical at this point to assume that a system EQ (or mix, for that matter) resembling the inverse of our hearing curve would be an easy solution, a listening test will quickly cause you to change your mind.
As is true with approaching any complex problem, we must always be hesitant to arrive at any simple, blanket solutions. Yet we can reasonably conclude a few things based on what we’ve learned.
First, it’s important to realize that a “flat” system response may not always sound good. Because we live with the non-linearities of our hearing response curve, we don’t notice them, but rather interpret them as “normal.” However, a tuned system response that is truly flat will quickly reveal the peaks in our hearing curve, and result in a harsh, warmth-lacking interpretation of the musical content.
Second, we must recognize that because the poor HF response of our hearing is interpreted as normal, most attempts to compensate in this range will sound overly “tingy,” “airy” or “sizzly.” While many instruments contain upper harmonics in the 8 kHz to 12 kHz range, we naturally hear these frequencies at much lower levels through our nonlinear response, and therefore interpret higher levels in this range as unnatural.
Third, because many of the upper-mid harmonics in electric guitars, pianos, B3 organs, and cymbals all reside in the 2 kHz to 5 kHz range (an area we are already hyper-sensitive to), we should be wary of this area becoming overly saturated.
When we combine this with the fact that most vocal microphones have a generous boost in this range, it can quickly become a dangerously harsh area of the mix. Often, small EQ dips in the individual channels, system EQ, or both may be necessary to prevent this buildup.
A Personal Approach
Over years of tuning live audio systems, I’ve consistently gravitated toward a response that gently slopes downward from the lower end of the spectrum, allowing even sub-bass reproduction consistent with our hearing curves, then gradually flattens from 100 Hz to 400 Hz or so.
The midrange remains flat for the most part, while the high end may drop off slightly, depending on the PA I’m working with. I typically reference a couple of tracks that have a decent amount of 2 kHz to 5 kHz content to make sure those ranges don’t become unpleasant.
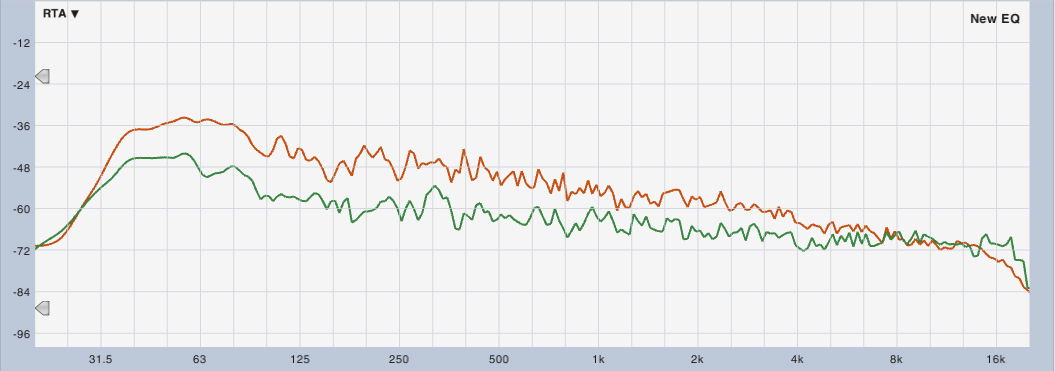
I’ve found that running an RTA with a long average (7 to 10 seconds) can be an extremely helpful tool when mixing. On songs when the band is going full-tilt, I’ve often observed that the mix feels the most balanced, enveloping, and defined when the spectral density of my mix is a consistent slope averaging at roughly -3 dB per octave. It can also be handy to help “drive between the lines” when I’ve been mixing for a few hours and my ears are tired, or when the mix position is in a spot where I can’t hear the PA as well as I’d like.
While understanding the “how-tos” of building a powerful, balanced mix is no small undertaking, applying a solid foundational knowledge of basic psychoacoustics is a bedrock. In a way, it’s almost like getting a peek at the other team’s playbook, and can help us avoid some of the more common mistakes in live mixing.
Editor’s Note: The author thanks Dr. Michael Santucci of Sensaphonics and Benj S. Kanters of Columbia College in Chicago for their collaboration and support with this article.