There are two ways to assess the quality of audio devices: measuring and listening.
Measuring is usually the better choice because the results are absolute, and repeatable because they avoid the vagaries of human hearing perception. But when measuring isn’t practical or possible, a listening test using a music source is perfectly fine.
For example, listening is needed to compare CD quality at a 44.1 KHz sample rate to “high-definition” audio at 96 KHz. Both will measure the same if the frequency response is limited to the audible range, but some people believe they sound different.
Another example is comparing MP3 bit-rates, especially higher values such as 256 versus 320 kbps. It’s pretty much impossible to “measure” the effect of lossy compression using traditional means because the frequency response changes from moment to moment.
Listening tests are also useful for comparing loudspeakers because there are so many variables such as off-axis response, dB per octave low frequency roll-off slope, distortion that varies continuously with volume level, and separate distortion amounts for the woofer and tweeter. These can be measured perfectly well in a million-dollar anechoic chamber, but not so well at home.
Further, it’s probably impossible to measure the subjective effect of devices that add distortion or other color intentionally. Does an Aphex Aural Exciter sound better than a BBE Sonic Maximizer? Do plugin versions of vintage compressors sound the same (or at least as good) as the original hardware? Does a tape-sim plugin really sound like tape?
Only you can decide what sounds “better” to you, though you might be fooled, or at least biased, by various factors such as knowing whether you’re hearing a real guitar amp or a plugin simulation. So verifying your own perception is another use for a listening test.
Performing a proper listening test is a lot more complicated than many realize, and several conditions must be satisfied for the results to be valid. When the perceived differences are subtle – and even when they’re not so subtle – you can’t just play one thing, then another, and proclaim a winner.
The differences between modern high-fidelity audio devices are usually very subtle, at least when operated at normal levels to avoid distortion or noise. More often than not, listening tests have shown repeatedly that people are unable to tell one competent audio device from another no matter how much they differ in price.
Testing Rules
First, and perhaps most important, a listening test must be blind. If the listener can see which device or source is playing, that will influence their opinion. Nobody is immune from sighted bias, and no reasonable person should object to being tested blind. If you’re so certain that you can tell HD audio from CD quality, then you should be able to do that when you can’t see which is playing.
Just as important, the audio sources being compared must be the same musical passage or sound sequence. You can’t compare devices by playing different parts of a song because the source sound itself changes! That makes it impossible to separate the source changes from any A/B device differences.
So it’s not valid to start playing a piece of music, then switch between A and B as the music continues. A section of music must be played through one device, then switch devices and play the same section again.
Further, you can’t just do this once because the listener has a 50-50 chance of being correct just by guessing. Therefore, at least five or six tests are needed – or even more – to be certain the listener really can hear a difference reliably. I’ll address the number of tests needed later in this discussion.
You can’t compare different performances either. A common mistake is comparing microphones or preamps by recording someone singing or playing a guitar with one device, then switching to the other device and performing again.
The same subtle details we listen for when comparing gear also differ between performances – for example, a bell-like attack of a guitar note or a certain sparkling sheen on a brushed cymbal. Nobody can play or sing exactly the same way twice or remain perfectly stationary. So that’s not a valid way to test microphones, preamps, or anything else. Even if you could sing or play the same, a change in mic position of even half an inch is enough to make a real difference in the frequency spectrum captured by the microphone.
The A and B volume levels must also be matched to within 0.1 dB, or as close to that as possible. Very small level differences often don’t sound louder or softer, but just slightly different. Larger volume differences have a substantial affect on perceived response due to Fletcher-Munson, where both low and high frequencies become more prominent at louder volumes.
You can match volume levels through electronic devices, such as preamps and equalizers, using a 1 kHz sine wave (click here to download a .wav file from my website). A decent voltmeter is also needed, though a recorder with a large analog VU meter is a reasonable second choice. One (1) kHz is standard for audio testing because it’s in the middle of the audio range to avoid the response errors many devices exhibit at the low and high frequency extremes.
However, when comparing acoustic sounds in the air, a better source for calibrating loudspeaker or microphone levels is pink noise that’s been band-limited to contain only midrange frequencies. Acoustic waves in a room create numerous peak and null locations only inches apart. The advantage of noise is that it contains multiple frequencies, so if your microphone is in a null at 1,000 Hz it’s probably not in a null at 900 Hz or 1,100 Hz. And as with sine waves, low and high frequencies are best avoided where loudspeakers and mics are further from flat.
Single Or Double?
There are two types of blind tests: single- and double-blind. With a single-blind test, one person (the tester) handles playing the music and switching the media or devices without letting the listener (the subject) know which is which. The tester knows but not the subject. The problem with single-blind tests is it’s possible for the tester to give a clue to the subject without meaning to or even realizing it.
In a double-blind test, even the tester doesn’t know which is which. So with wine tasting tests or drug trials, for example, the wine or medicine is labeled only “A” or “B” and the tester merely keeps track of each subject’s choices. Those choices are then given to someone else to tabulate, and only that person knows the identity of A and B.
A double-blind test is difficult to set up and implement, and most people won’t go to that much effort. I believe a single-blind test can be sufficient, especially for informal tests between friends that won’t be published in a peer-reviewed journal.
But there are still important ground rules: The person testing must not look at the test subject, and it’s better if they can’t even see each other. When I test people blind in my home studio, I’m at my computer while they sit or stand behind me. They can’t see my face, and my body blocks the screen and my hands on the keyboard.
Most audio tests compare only two things at a time, such as a Wave file versus an MP3 copy, or D/A converters with music playing through one then the other. The tester plays example A and asks the subject which version she thinks is playing. Then the tester can switch to example B and ask again. It’s OK, and even suggested, to occasionally play the same source twice or even three times in a row. Most subjects won’t expect that, so it can further confirm whether they’re really hearing a difference or just guessing.
Then the same test is repeated enough times to be sure the subject didn’t succeed once or twice by chance. Of course, the tester must keep clear notes of which version is played every time. It’s probably simpler to establish a sequence of A/B switches in advance, then you won’t have to keep stopping to note them all during the test. A typical sequence might be A, B, B, A, B, A, A, A, B, etc. Then during the test you can write the subject’s choices underneath each letter.
Note that being consistently wrong is as significant as being right. If you listen blind to compare media players costing $30 versus $1,000 and you pick the cheaper player every time, then you really did hear a difference. So being correct only one time in 10 is the same as being correct nine times out of 10. You just thought the cheap player sounded better. And maybe it really was better.
Finally, some believe that blind tests put the listener on the spot, making it more difficult to hear differences that really do exist. Blind testing is the gold standard for all branches of science, especially when evaluating perception that is subjective. Blind tests are used to assess the effectiveness of pain medications as well as for food and whiskey tasting comparisons.
There’s no reason it can’t work just as well with audio. Again, if someone is so certain of their hearing, then they should be able to do it blind. It’s true that some types of degradation become more obvious with experience.
Both MP3-type lossy compression and dynamic noise reduction add a slight hollow sound that becomes more obvious with experience and repeated listening. But learning to notice subtle artifacts is not the same as being “stressed” by having to listen blind. It’s reasonable to assume that anyone serious enough about audio fidelity to take a listening test already knows what to listen for.
Correct By Chance
Nobody will miss a 10 dB midrange boost on a typical music track, but some claim to be able to hear very subtle differences that others might miss. In this case, enough trials are needed to be sure they didn’t guess correctly by chance.
If A then B are played only once and the subjects are correct, there’s a 50 percent chance they were right just by guessing. If they’re correct two times out of two, it’s still 25 percent likely they just guessed correctly. Formula 1 shows what percentage of correct responses we can expect just by guessing at random.
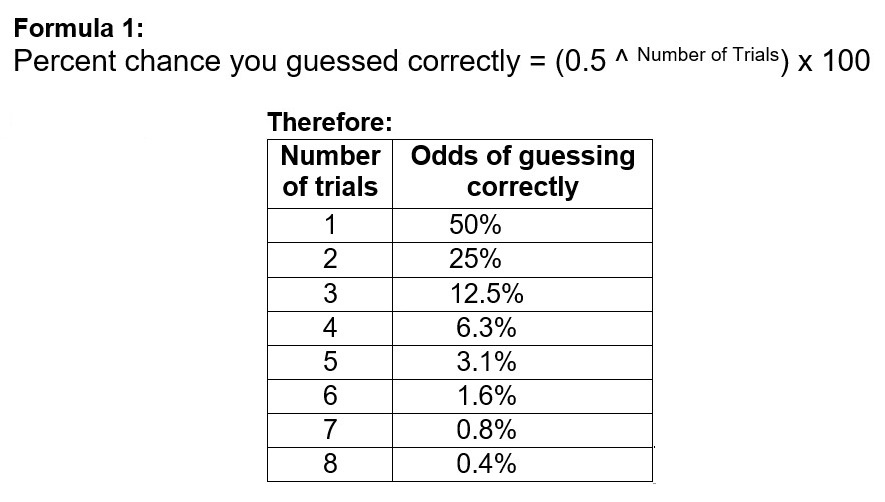
If someone insists he can hear some soft artifact or other anomaly, it’s not unfair to expect him to be correct every single time. If a difference is so obvious that “even my maid can hear it,” as one well-known mix engineer once claimed to me, then he ought to be able to choose correctly every time, no matter how many trials there are.
However, if you test a large enough group of people, it’s likely some of them will be correct by chance alone. For example, if you give a test having five trials (97 percent reliability) to 100 people, three of them could be correct even if everyone just guessed at random! The solution is to ask those same people to do five trials a second time. If they’re correct all five times again, then the odds of having guessed correctly by chance are only 3 percent of 3 percent = 0.09 percent. And in that case they likely do really hear a difference.
Note that the number of trials needed to ensure someone is not correct merely by chance should not be confused with confidence interval in statistics. That’s not the correct term because confidence is related to testing the general population. If you test 1,000 people to see how many can hear the difference between two types of dither, it gives you a good sense of whether most people can hear a difference.
But for audio tests, it doesn’t matter what “most people” can or cannot hear. All that matters is what you or the test subject can identify reliably.
Be sure to go here to check out Part 2 of this article.