
Using The Wake Word
When testing the input path, the wake word must be used to activate the smart speaker, causing it to anticipate a spoken command and record a few seconds of audio. One option is for the test operator to just say the wake word, as if giving the device a command, and then immediately generate the test signal from the mouth simulator. This works, but the timing between the wake word and the test signal may vary from test to test.
Another option is to record a person saying the wake word and then prepend it to the stimulus signal using an audio waveform editor (i.e., insert it at the beginning of an audio file containing the stimulus). In this case, to conduct a test, the wake word with stimulus is simply played through the mouth simulator at the required level. With this method, the time between the wake word and the stimulus is constant from test to test. This option also works well when the DUT is inside a test chamber and the operator and audio analyzer are located outside the chamber.
The process of activating the smart speaker with the wake word followed by the audio stimulus signal will trigger the DUT to record several seconds of audio and upload it to the IVA for speech recognition processing. To complete the analysis requires retrieving this recorded audio file from the back-end server, converting it to the .wav format, and analyzing it with the audio analyzer control software.
Details of this process will vary, depending on which IVA is used. For example, the popular Alexa service has a web portal where users can log into their account to manage interactions with connected smart devices. In the Settings menu under History, there is a record of each interaction with a connected smart device, including a date/time stamp, a transcription of the interpreted command and a tool to play the recorded audio on the PC’s speakers. Using the web developer mode features built into web browsers, it’s possible to retrieve a hyperlink that will enable you to download the recorded .wav file directly. You can then open it in the audio analyzer software for analysis.
Here’s an example that illustrates a test of the input path of a smart speaker using the Transfer Function measurement with a stimulus waveform consisting of speech chatter. The signal, which was recorded at a night club with many people talking at the same time, is essentially random speech noise. As shown in Figure 2, the smart speaker wake word was prepended to the stimulus waveform. For the transfer function measurement, the system triggers on the wake word and includes it in the analysis with the rest of the stimulus signal.
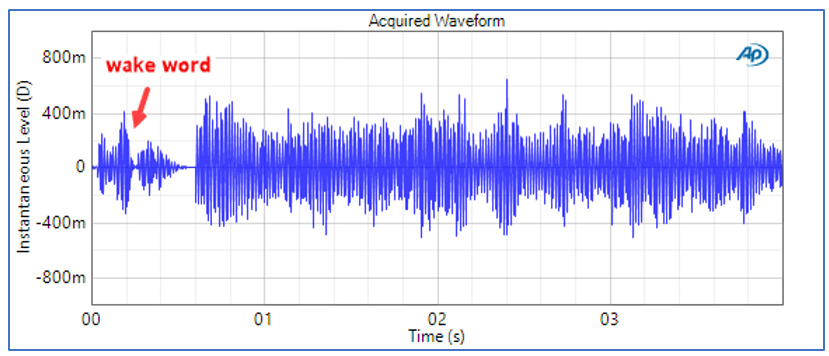
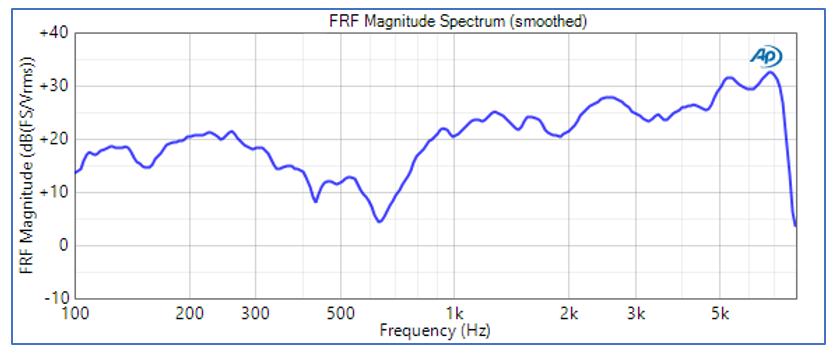
The frequency response magnitude derived by retrieving the recorded .wav file from the IVA’s server and analyzing it with respect to the stimulus signal is shown in Figure 3. In this case the mouth simulator was driven at a level such that the rms level measured at the MRP was 89 dBSPL.
Next, let’s move on to an example featuring a test of the input path of the same smart speaker using a log-swept sine stimulus. Figure 4 shows the stimulus waveform for a 0.35-second long sweep from 50 Hz to 8 kHz, with a pilot tone and the wake word inserted before the chirp signal. The analyzer triggers on the pilot tone and uses the pilot tone frequency to correct for the slight sample clock difference between the DUT and the analyzer. In this case, the wake word and pilot tone are not included in the analysis of the frequency response.
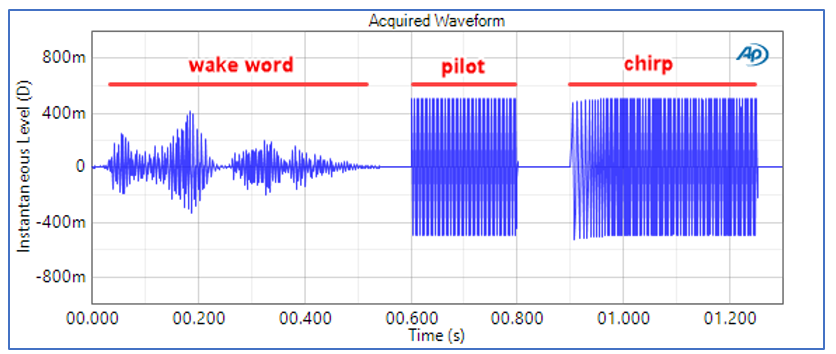
Figure 5 depicts the acoustic level response of the smart speaker input path for sweep lengths of 0.35, 1.0, and 4.0 seconds.
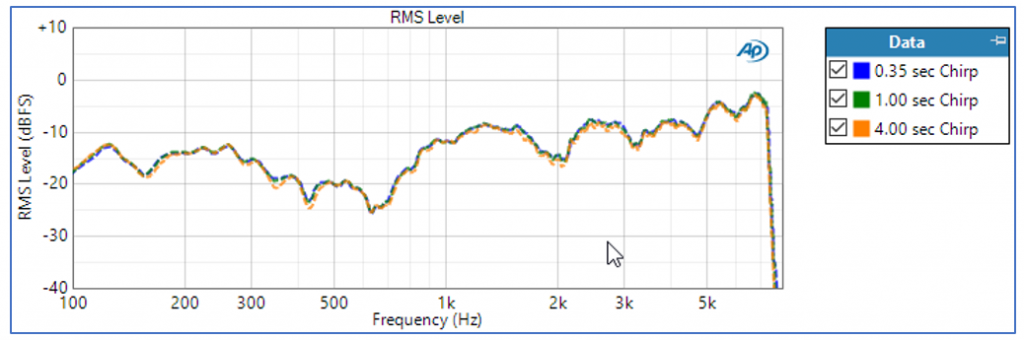
Some interesting observations:
— The response curves from the chirp analysis and the transfer function measurement with a speech signal, above, are remarkably similar in shape.
— The response to the chirp stimulus does not vary much with the length of the sweep.