Editor’s Note: A few weeks ago, we presented part 1 in this 2-part article series. If you’ve already read part 1, which begins directly below, click here to go directly to part 2.
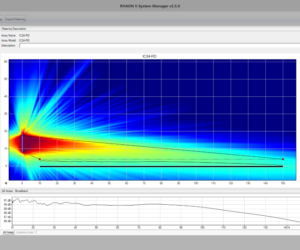
Smart loudspeakers (which we’ll call “smart speakers” from here on out) are a relatively new class of consumer audio device with unique characteristics that make testing their audio performance difficult. In this application note, we provide an overview of smart speaker acoustic measurements with a focus on frequency response – the most important objective measurement of a device’s audio quality.
Background
A smart speaker is an internet-connected (usually wireless) powered speaker with built-in microphones that enables users to interact with an Intelligent Virtual Assistant (IVA) using voice commands. Using voice only, it can be directed to perform tasks such as play audio content (news, music or podcasts, etc.) from the internet or a connected device, control home automation devices, or even order items from a connected online shopping service.
Amazon was the first major company to release a smart speaker, called the Echo, with its IVA known as Alexa, and it still has the dominant market share. Other significant entrants in this space include Alphabet (Google Assistant on Google Home speakers), Apple (Siri on HomePod speakers), Microsoft (Cortana on 3rd-party speakers), Samsung (Bixby on Galaxy Home speakers) and a few others from China, Japan and South Korea.

From humble beginnings when first introduced, smart speakers quickly skyrocketed in popularity. In November 2014, shortly after the release of the first-generation Amazon Echo, a popular technology review site said of the event, “… the online retailer took another strange turn in the world of hardware by unveiling a weird wireless speaker with, Siri-like ability to recognize speech and answer questions.”[1]
But since then the proliferation of smart speakers has exploded, and strong growth is projected to continue for at least the next five years. Within three years of that 2014 introduction, the USA alone had an installed base of 67 million smart speakers in households, and that number grew by 78 percent in 2018 to 118 million units.[2] The global smart speaker market was valued at $4.4 billion (U.S.) in 2017 and is projected to reach $23.3 billion by 2025.[3] Several companies with IVAs license the technology to other manufacturers – for example, both Bose and Sonos offer Alexa-enabled and Google Assistant-enabled smart speakers.
And not only speakers are getting “smart;” IVA technology, with microphones and loudspeakers to support it, is being added to all sorts of devices like refrigerators, microwave ovens and set top boxes, enabling voice control of those devices. Additionally, most smartphones can also play the role of a smart speaker.

Smart Speaker IVAs
An interaction with a smart speaker begins with a specific “wake word” or phrase, for example, “Alexa” for Amazon, “Hey Siri” for Apple, etc., followed by a command. In their normal operating mode, smart speakers are in a semi-dormant state, but are always “listening” for the wake word, which triggers them to acquire and process a spoken command.
In terms of speech recognition, smart speakers themselves are only capable of recognizing the wake word (or phrase). The more computationally intensive speech recognition and subsequent processing is done by the Intelligent Virtual Assistant on a connected server.[4] The IVA converts the user’s speech to text and attempts to interpret the command. To invoke the requested response from the device, the spoken command must contain a sequence of keywords recognizable by the IVA. A successful interaction may result in the requested action being taken by the IVA (e.g., “Set a timer for 10 minutes.”) or by a connected web service (e.g., “Play an internet radio station.”).
Audio Subsystems
Smart speakers contain several distinct audio subsystems, including:
• A microphone array.
• A powered (active) loudspeaker system.
• Front-end signal processing algorithms for tasks such as beamforming, acoustic echo cancellation and noise suppression.
An array of microphones is used instead of a single microphone to enable the device to take advantage of beamforming, a signal processing technique that can effectively increase the signal-to-noise ratio of the speech signal sent to the IVA for processing. [5] Based on correlations among signals received at different microphones in the array, a beamforming algorithm can detect the most likely direction of the talker in a room and, in a sense, focus on that direction by combining the various microphone signals in a way that attenuates signals coming from other directions. This can effectively reduce the level of ambient noise and room reverberation in the speech signal sent to the IVA. Noise suppression may also be used to reduce the level of non-speech like signals.
Ideally, a smart speaker will be able to respond to spoken commands (by first recognizing the wake word) even while playing audio content such as music or speech in a room. Acoustic echo cancellation (AEC) is essential for preventing the loudspeaker output from completely masking the microphone input for this task. The signal being played on the loudspeaker system can be used as a reference signal for the AEC algorithm, enabling it to ignore the content being played and to recognize the wake word. Typically, playback is paused after the wake word is detected, to help improve command recognition.